Bottom Up Top Down Detection Transformers for Language Grounding in Images and Point Clouds
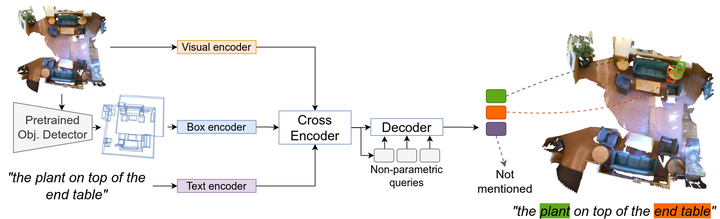
Most models tasked to ground referential utterances in 2D and 3D scenes learn to select the referred object from a pool of object proposals provided by a pre-trained detector. This is limiting because an utterance may refer to visual entities at various levels of granularity, such as the chair, the leg of the chair, or the tip of the front leg of the chair, which may be missed by the detector. We propose a language grounding model that attends on the referential utterance and on the object proposal pool computed from a pre-trained detector to decode referenced objects with a detection head, without selecting them from the pool. In this way, it is helped by powerful pre-trained object detectors without being restricted by their misses. We call our model Bottom Up Top Down DEtection TRansformers (BUTD-DETR) because it uses both language guidance (top down) and objectness guidance (bottom-up) to ground referential utterances in images and point clouds. Moreover, BUTD-DETR casts object detection as referential grounding and uses object labels as language prompts to be grounded in the visual scene, augmenting supervision for the referential grounding task in this way. The proposed model sets a new state-of-the-art across popular 3D language grounding benchmarks with significant performance gains over previous 3D approaches (12.6% on SR3D, 11.6% on NR3D and 6.3% on ScanRefer). When applied in 2D images, it performs on par with the previous state of the art. We ablate the design choices of our model and quantify their contribution to performance. Our code and checkpoints can be found at the project website: https://butd-detr.github.io/