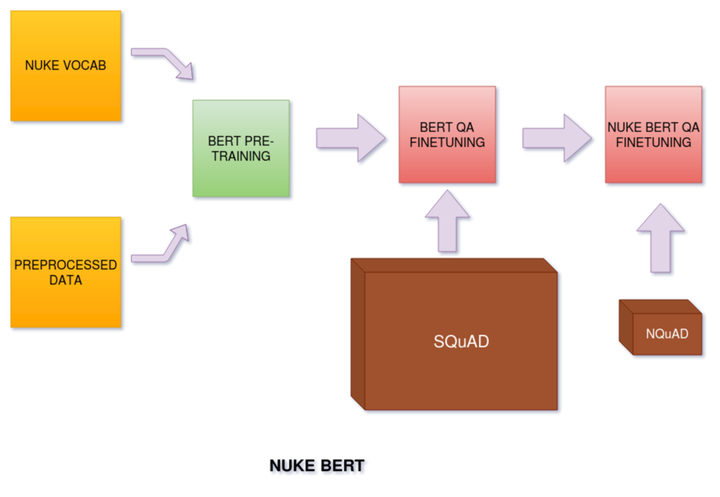
Significant advances have been made in recent years on Natural Language Processing with machines surpassing human performance in many tasks, including but not limited to Question Answering. The majority of deep learning methods for Question Answering targets domains with large datasets and highly matured literature. The area of Nuclear and Atomic energy has largely remained unexplored in exploiting available unannotated data for driving industry viable applications. To tackle this issue of lack of quality dataset, this paper intriduces two datasets: NText, a eight million words dataset extracted and preprocessed from nuclear research papers and thesis; and NQuAD, a Nuclear Question Answering Dataset, which contains 700+ nuclear Question Answer pairs developed and verified by expert nuclear researchers. This paper further propose a data efficient technique based on BERT, which improves performance significantly as compared to original BERT baseline on above datasets. Both the datasets, code and pretrained weights will be made publically available, which would hopefully attract more research attraction towards the nuclear domain.